Question Answering System
Final project of the 5th semester Application Of AI course. Have a look at the code on my Github: Github
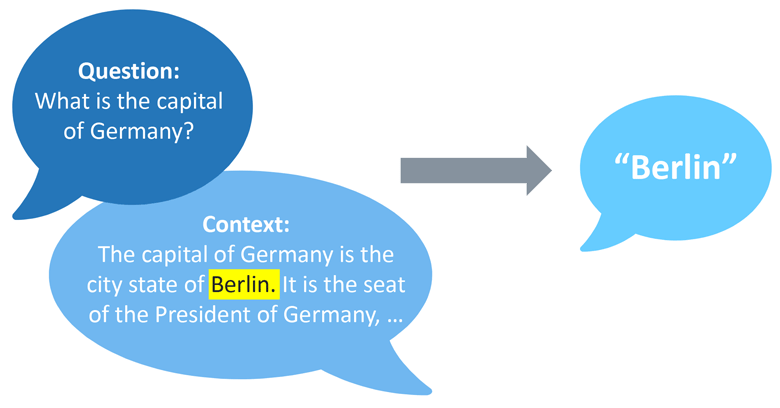
Image from: Link
Libraries: transformers, elasticsearch, nltk, sklearn, pandas, numpy
Brief Overview:
Goal
- Get an answer from a large corpus of text documents
Methodology
- Used elasticsearch to index the documents and get the relevant ones with a query containing the question
- Leveraged Transformer API to extract the answers from the relevant documents
What did I learn?
- Working with search engine elasticsearch to index and query documents
- Understanding and using transformer models for NLP tasks
- Combine different concepts in one system
Results
- First place in the course competition
Introduction
The goal of this project is to showcase the covered concepts and methods from the semester and use them to create a Question Answering System. This was a team project with a size of two.
To create a Question Answering System, one must understand how to interpret and work with text data. During the semester, we started with the basics of NLP (tokenization, stemming/lemmatization, bag-of-words, NER), continued with Machine Learning, and ended the course with more advanced concepts from Deep Learning, where we also covered large Language models based on the transformer architecture.
Here is a top-level overview of the sequence of the System:
- Elasticsearch is used as the search engine to index documents and retrieve the relevant ones, provided a query.
- The Transformer API from Hugging Face is used to extract the answers from the important documents.
Components of the QA-System
Our QA-System is divided into 4 segments: question processing, document retrieval, answer retrieval and answer post processing.
Question Processing
We tried various methods to enhance the query: removing stopwords, numbers, and punctuation. To our astonishment, none of them increased the chosen performance metric, precision@k (number of relevant documents in the top-k set of retrieved documents). Therefore, we presented the question to Elasticsearch without any preprocessing.
Document Retrieval
We used k=5 to retrieve 5 relevant documents from Elasticsearch. The query was boosted (increased weights for a specific field/column), which slightly increased the p@k.
Answer Retrieval
The answer was extracted using a model from the transformer API provided by Hugging Face. For the model, we used DistilBERT base cased distilled SQuAD, which is a pretrained and finetuned model on SQuAD and fits perfectly for the requested task. DistilBERT is a smaller version of BERT created through the concept known as knowledge distillation, a compression technique in which a smaller model is trained to reproduce the behavior of a larger model.
For each document, two answers were extracted, bringing the count of answers per question to 10. Those 10 answers were ranked using the score of Elasticsearch per document and the score of the transformer model.
Answer Post Processing
Some of the Answers had some trailing punctuation or relicts of the wikipedia format. Stuff like that was removed in the last step.
Results
There were eight teams in the course, and we achieved the best score with 50.6%. The score is computed by multiplying the match score (how well the answers overlap in terms of tokens) with the rank of the answer.