Hashtag-Analysis
#66DaysofData
Analysis of the Tweets under the 66DaysofData Hashtag. The challange was created by Data-Science-Youtuber Ken Jee. Have a look at the code on my Github: Github
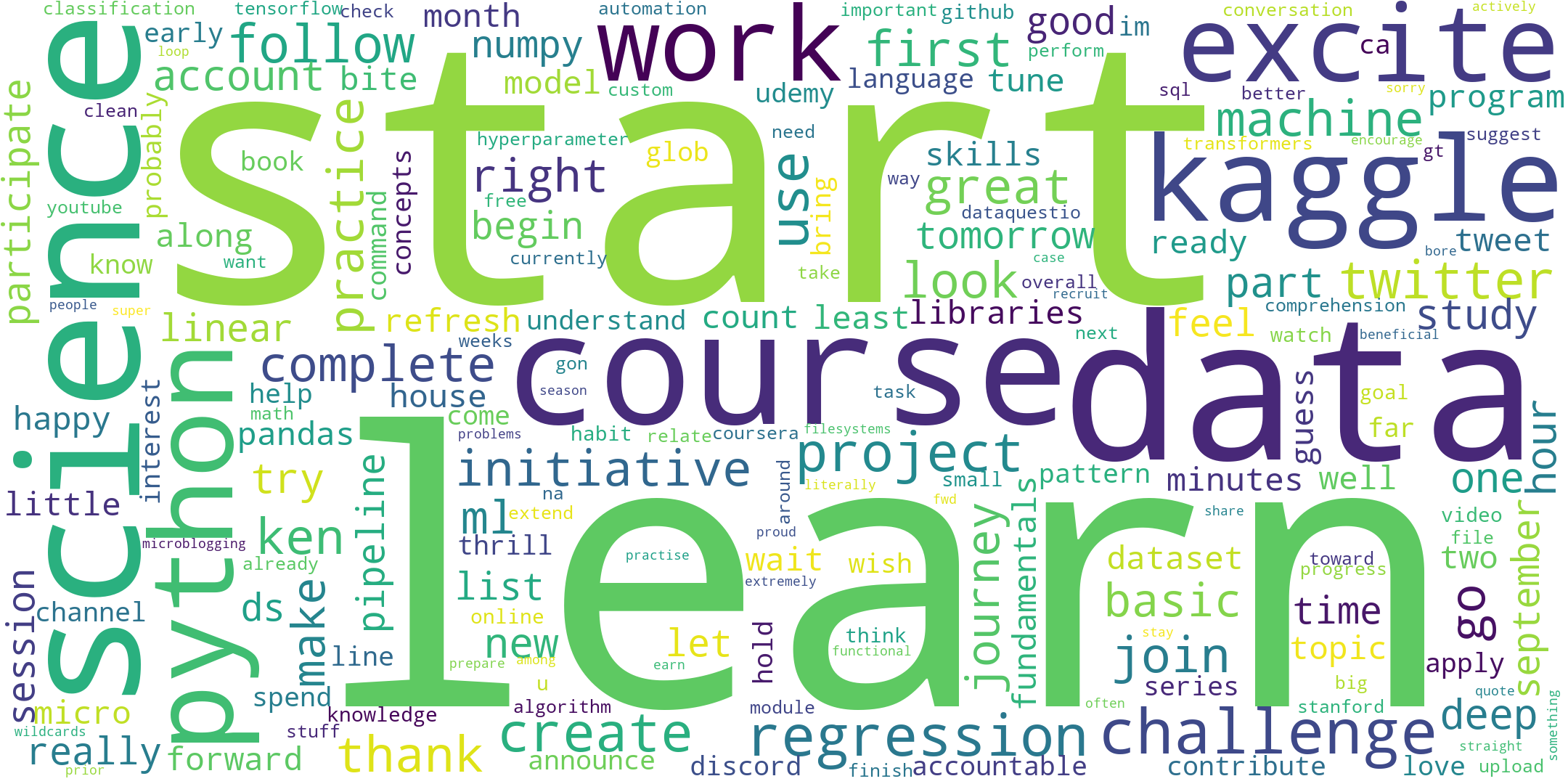
Libraries: numpy, pandas, searchtweets, tweepy, nltk, matplotlib, wordcloud, streamlit
Brief Overview:
Goal
- Analyze tweets posted under the hashtag: 66DaysofData.
- Independently collect data and create a usable dataset
- Opportunity to engage in text analytics (NLP).
Methodology
- Tweepy for tweets up to 7 days in the past
- Searchtweets for hisrotical tweets
Results(as of 2023/04/12)
- 40191 tweets from #66DaysofData collected
- Tweets from 2020-08-29 to 2023-04-07
- 1902unique participants took part in the challenge
- Streamlit Dashboard
What did I learn?
- Methodology for data collection.
- Data collection over a longer period of time
- Preparing and dealing with text for a data analysis
- Deploying a web app with Streamlit share
ToDo
- How many did finish the challenge?
- What are the main topics?
- Differences between first and second round
- Sentiment analysis
- Topic analysis
Introduction
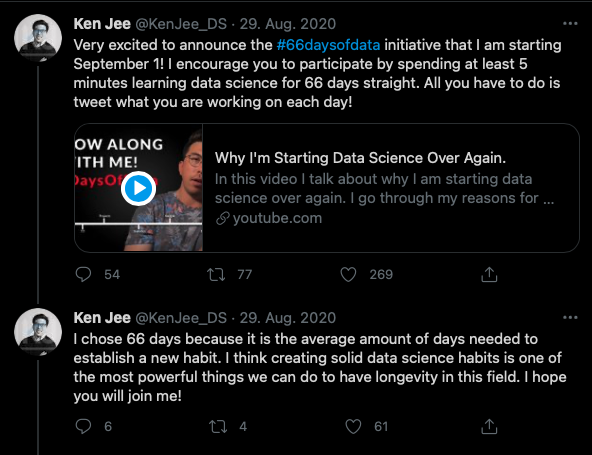
The #66DaysofData Challenge started on 01.09.2020 and was created by data scientist and youtuber Ken Jee. The goal of the challenge is to spend at least five minutes every day on a topic related to data science and share the progress on social media (mainly via Twitter).
Since I have been following Ken Jee on YouTube for a while, I also started the challenge on 01.09 and published what I did every day on Twitter. After the first month, I had the idea to collect the tweets. I was interested in the topics that the participants are doing and it seems like a great project to do.
Data Gathering
I started collecting the tweets two month into the challenge (29.10.2020) - which was somewhat of a problem. I used tweepy to manually query every week to get the current tweets (tweepy returns tweets up to 7 days in the past). By now, I use a cron-job to do the query automatically every 6 days.
For tweets older than 7 days there is the premium API "Search Tweets: Full ArchiveSandbox" but this is limited for free users and does not allow to remove unimportant tweets (e.g. retweets), so I had to do queries over several months to finally cover the whole period. I queried the premium API with seachtweets.
Data Cleaning
- Removed duplicate tweets
- Created specific data and time columns
- Analyzed the time and date of tweets to figure out if I managed to collect every tweet
- Used regex to create new columns for used hashtags, linked persons, day of the challenge and links.
- Worked with the nltk library to tokenize, remove stop words and lemmatize the text data
Results
The Results are shown in a dashboard made with streamlit. Streamlit describes itself as 'a faster way to build and share data apps'. The dashboard shows quntitative data about the the tweets and paricipants can create a wordcloud based on their tweets. The web app can be accessed here.